Spatiotemporal PINNs: Disease Spread as a Reaction-Diffusion System
Extending physics-informed networks from ODEs to PDEs with second spatial derivatives via autograd
PINN
PDE
epidemiology
Python
deep learning
Author
Jong-Hoon Kim
Published
April 25, 2026
1 From time to space-time
The previous posts in this series worked with compartmental ODEs — dynamics in time alone. Real epidemics have spatial structure: disease spreads outward from index cases, population density varies across a region, and interventions can be geographically targeted.
The natural continuous-space extension is a reaction-diffusion system — a PDE that combines local transmission (reaction) with spatial movement of infectious individuals (diffusion) (1,2). Fitting such a PDE from sparse spatiotemporal observations is exactly the problem that spatiotemporal PINNs are designed for.
This post shows:
The 1-D reaction-diffusion SIR PDE and its finite-difference (FD) reference solution.
A spatiotemporal PINN with \((x, t)\) inputs — the network learns the full field \((s, i, r)(x, t)\).
How second spatial derivatives are computed via two nested autograd.grad calls.
Neumann boundary conditions (zero-flux) enforced as an additional loss term.
Tip
What you need
pip install torch scipy matplotlib numpy
Tested with torch 2.11, scipy 1.17, Python 3.11. Training takes ~5–10 min on CPU with the settings below.
2 The reaction-diffusion SIR model
Adding spatial diffusion to the SIR equations (3,4) in fraction form gives a system of PDEs on \(x \in [0, L]\), \(t \in [0, T]\):
The diffusion coefficient\(D\) controls how rapidly infectious individuals spread spatially; \(\beta\) and \(\gamma\) retain their epidemiological interpretation.
Boundary conditions — zero-flux (Neumann) at both ends, preventing population leaving the domain:
The resulting dynamics are a travelling wave of infection propagating outward from the source (5). The wave speed is approximately \(c_w \approx 2\sqrt{D(\beta - \gamma)}\) — a result analogous to Fisher’s travelling wave (5,6), depending on both diffusion and the net growth rate \(\beta - \gamma\).
3 Finite-difference reference solution
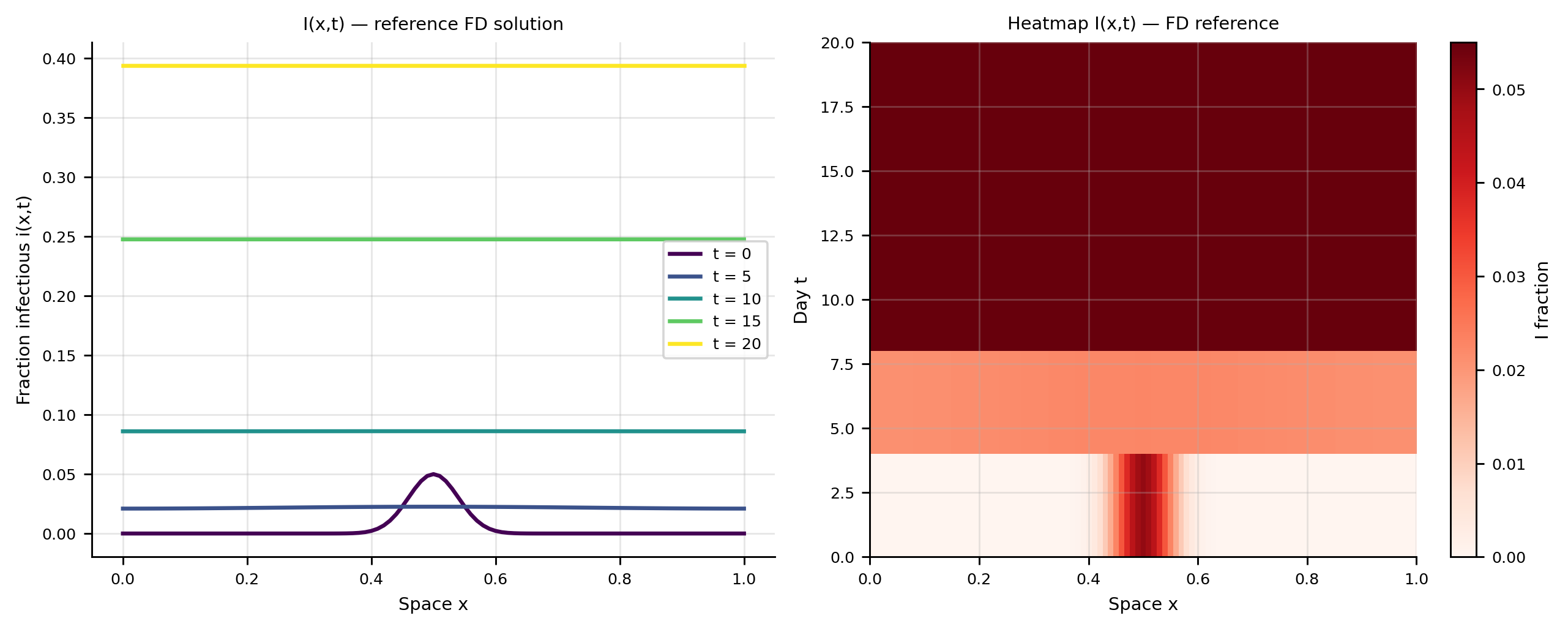
Before training the PINN, we generate a high-accuracy reference solution using explicit finite differences for validation.
Code
import numpy as npimport matplotlib.pyplot as pltimport matplotlib.gridspec as gridspecimport torchimport torch.nn as nntorch.manual_seed(42); np.random.seed(42)plt.rcParams.update({"figure.dpi": 130,"axes.spines.top": False,"axes.spines.right": False,"axes.grid": True,"grid.alpha": 0.3,"font.size": 8,"axes.titlesize": 8,"axes.labelsize": 8,"xtick.labelsize": 7,"ytick.labelsize": 7,"legend.fontsize": 7,})C_S, C_I, C_R ="#2196F3", "#F44336", "#4CAF50"C_PINN ="#9C27B0"# ── Simulation parameters ──────────────────────────────────────────────────────L =1.0# spatial domain [0, L]T_end =20.0# time horizon (days)D_true =0.02# diffusion coefficientbeta_t =0.40# transmission rategamma_t =0.10# recovery rateI0_amp =0.05# initial peak prevalenceI0_width =0.04# spatial width of initial outbreak (variance)print(f"Estimated wave speed: {2*np.sqrt(D_true*(beta_t-gamma_t)):.4f} L/day")print(f"Expected wave travel in {T_end} days: "f"{2*np.sqrt(D_true*(beta_t-gamma_t))*T_end:.2f} L units")
Estimated wave speed: 0.1549 L/day
Expected wave travel in 20.0 days: 3.10 L units
Code
def fd_sir_1d(L=1.0, T=20.0, Nx=101, Nt=10_000, beta=0.40, gamma=0.10, D=0.02, I0_amp=0.05, I0_width=0.04, save_times=(0, 5, 10, 15, 20)):""" Explicit finite-difference solution of the 1D reaction-diffusion SIR. Neumann (zero-flux) BCs enforced via ghost-point extrapolation. Stability criterion: D * dt / dx^2 < 0.5. """ dx = L / (Nx -1) dt = T / Nt x = np.linspace(0, L, Nx)# Stability check cfl = D * dt / dx**2assert cfl <0.5, f"CFL = {cfl:.3f} >= 0.5, solver unstable — reduce dt or D"# Initial conditions I0 = I0_amp * np.exp(-(x - L/2)**2/ (2* I0_width**2)) S0 =1- I0 R0 = np.zeros(Nx) S, I, R = S0.copy(), I0.copy(), R0.copy()def laplacian(u):"""Zero-flux Laplacian via ghost-point BCs.""" lap = np.zeros(Nx) lap[1:-1] = (u[:-2] -2*u[1:-1] + u[2:]) / dx**2 lap[0] =2* (u[1] - u[0]) / dx**2# mirror BC lap[-1] =2* (u[-2] - u[-1]) / dx**2return lap snaps = {0: (S.copy(), I.copy(), R.copy())}for n inrange(Nt): dS = D * laplacian(S) - beta * S * I dI = D * laplacian(I) + beta * S * I - gamma * I dR = D * laplacian(R) + gamma * I S = np.clip(S + dt * dS, 0, 1) I = np.clip(I + dt * dI, 0, 1) R = np.clip(R + dt * dR, 0, 1) t_now = (n +1) * dtfor ts in save_times[1:]:ifabs(t_now - ts) < dt /2and ts notin snaps: snaps[ts] = (S.copy(), I.copy(), R.copy())return x, snapsx_fd, snaps_fd = fd_sir_1d( L=L, T=T_end, Nx=101, Nt=10_000, beta=beta_t, gamma=gamma_t, D=D_true, I0_amp=I0_amp, I0_width=I0_width, save_times=(0, 5, 10, 15, 20))
The infection wave originates at the centre (\(x = 0.5\)) and propagates outward, reaching the boundaries by \(t \approx 15\)–\(20\) days.
4 Spatiotemporal PINN
The spatiotemporal PINN extends the framework of Raissi et al. (7) from ODEs to PDEs, following the same collocation-point approach used in subsurface flow (8) and other PDE inverse problems.
4.1 Architecture
The network maps normalised coordinates \((\tilde x, \tilde t) = (x/L,\; t/T_{\max}) \in [0,1]^2\) to compartment fractions:
The physics loss evaluates the reaction-diffusion PDE residuals at \(M\) random collocation points \(\{(x_m, t_m)\}\) sampled uniformly in \((0,1)^2\):
\[
\mathcal{L}_\text{PDE} = \frac{1}{M}\sum_m
\Bigl[\underbrace{\bigl(\partial_t \hat s - D\,\partial_{xx}\hat s + \beta\,\hat s\,\hat i\bigr)^2}_{\text{S residual}}
+ \underbrace{\bigl(\partial_t \hat i - D\,\partial_{xx}\hat i - \beta\,\hat s\,\hat i + \gamma\,\hat i\bigr)^2}_{\text{I residual}}
+ \underbrace{\bigl(\partial_t \hat r - D\,\partial_{xx}\hat r - \gamma\,\hat i\bigr)^2}_{\text{R residual}}\Bigr]
\]
Both \(\partial_t\) and \(\partial_{xx}\) are computed via automatic differentiation:
First-order time derivative: one autograd.grad call w.r.t. \(t\).
Second-order spatial derivative: two nested autograd.grad calls w.r.t. \(x\).
The diffusion term \(D\,\partial^2 u / \partial x^2\) requires the second derivative of the network output w.r.t. \(x\). The first call autograd.grad(s, x, ..., create_graph=True) returns \(\partial s / \partial x\) and keeps the computation graph intact. The second call autograd.grad(ds_dx, x, ...) then differentiates this first derivative w.r.t. \(x\) again, yielding \(\partial^2 s / \partial x^2\).
Both calls require create_graph=True because we need second-order gradients to flow back through the physics loss to the network weights during L.backward().
5.2 Neumann boundary conditions
Zero-flux BCs (\(\partial s/\partial x = \partial i/\partial x = 0\) at \(x = 0\) and \(x = 1\)) are enforced as an additional loss:
Code
def bc_loss(model, t_bc):""" Zero-flux Neumann BCs at x = 0 and x = 1. t_bc: (B,) normalised time points at the boundary. """ ones = torch.ones_like(t_bc)# ── x = 0 boundary ──────────────────────────────────────────────────────── x0 = torch.zeros_like(t_bc).requires_grad_(True) y0 = model(x0, t_bc) s0, i0 = y0[:, 0], y0[:, 1] ds_dx0 = torch.autograd.grad(s0, x0, ones, create_graph=True, retain_graph=True)[0] di_dx0 = torch.autograd.grad(i0, x0, ones, create_graph=True)[0]# ── x = 1 boundary ──────────────────────────────────────────────────────── x1 = torch.ones_like(t_bc).requires_grad_(True) y1 = model(x1, t_bc) s1, i1 = y1[:, 0], y1[:, 1] ds_dx1 = torch.autograd.grad(s1, x1, ones, create_graph=True, retain_graph=True)[0] di_dx1 = torch.autograd.grad(i1, x1, ones, create_graph=True)[0]return (ds_dx0**2+ di_dx0**2+ ds_dx1**2+ di_dx1**2).mean()def ic_loss(model, x_ic, s_ic, i_ic):"""Match initial conditions at t = 0.""" t0 = torch.zeros_like(x_ic) pred = model(x_ic, t0) ls = ((pred[:, 0] - s_ic) **2).mean() li = ((pred[:, 1] - i_ic) **2).mean()return ls + lidef data_loss(model, x_obs, t_obs, i_obs):"""MSE on sparse I(x,t) observations.""" pred = model(x_obs, t_obs)return ((pred[:, 1] - i_obs) **2).mean()
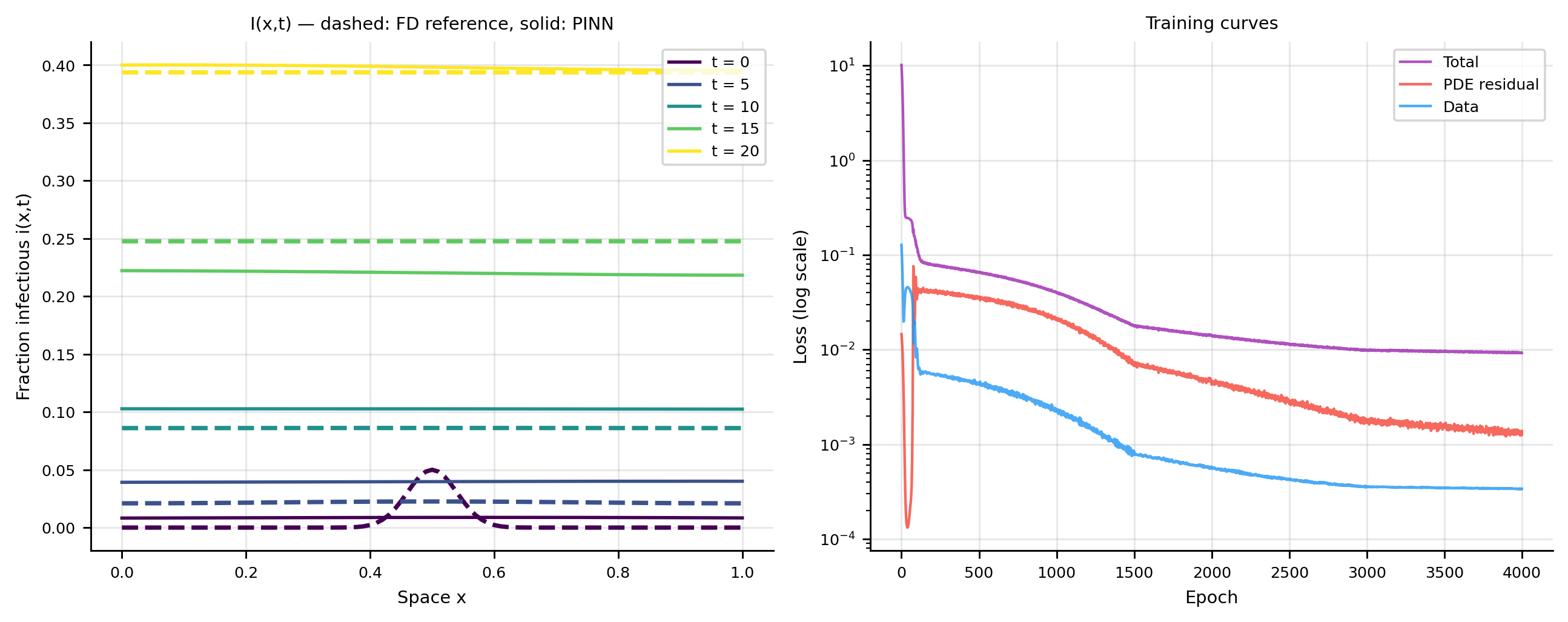
6 Training data preparation
The PINN is trained on:
PDE physics at 500 random collocation points in \((0,1)^2\).
Initial conditions at \(t = 0\) on a 101-point spatial grid.
Boundary conditions at \(x = 0\) and \(x = 1\) on random time points.
Sparse observations of \(I(x,t)\) from the FD reference at \(t \in \{5, 10, 15, 20\}\), sampled at 20 random spatial locations each.
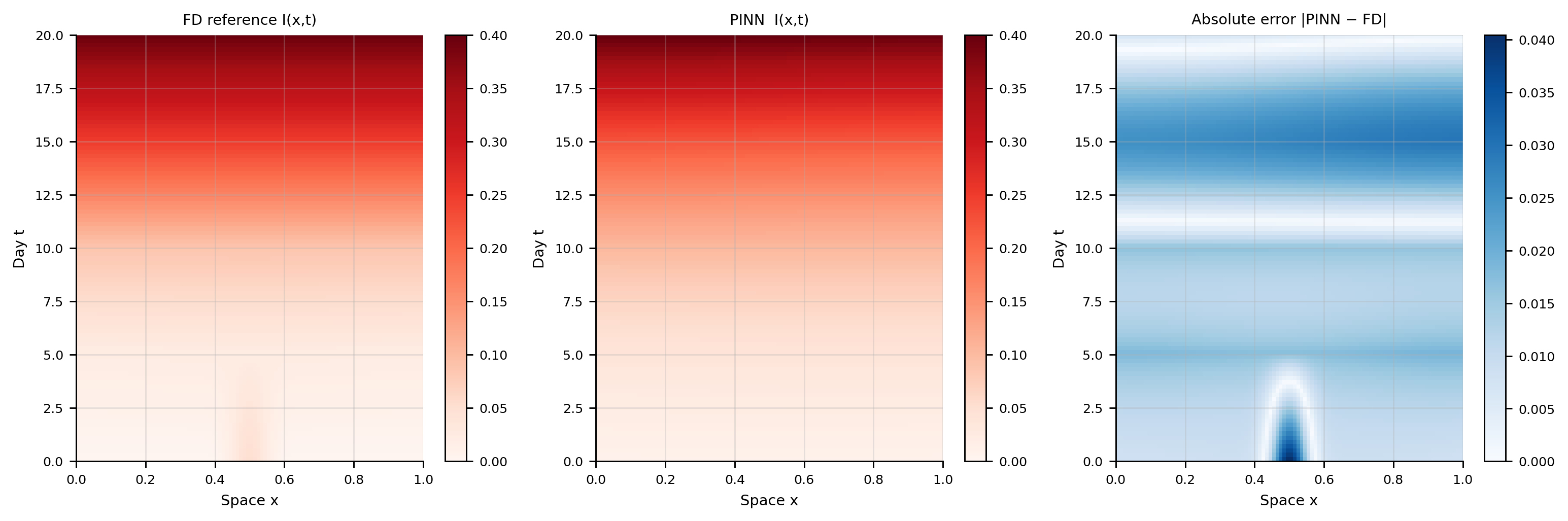
Mean absolute error: 0.01395
Max absolute error: 0.04044
Note
Spatial field recovery vs. parameter identifiability
The PINN reconstructs the \(I(x,t)\) field with low mean absolute error, but the recovered \(\beta\) and \(\gamma\) may differ from the true values. This is expected: in a reaction-diffusion system the three parameters \((D, \beta, \gamma)\) interact — multiple combinations can produce spatially similar infection waves. Reliable parameter recovery requires additional constraints such as richer observations (multiple compartments, multiple spatial transects), stronger regularisation toward biologically plausible ranges, or hierarchical Bayesian priors. The low field MAE confirms that the PINN has found a physically consistent solution, even if that solution is not the unique inverse-problem answer.
9 How spatiotemporal PINNs differ from ODE PINNs
Feature
ODE PINN (SIR)
PDE PINN (reaction-diffusion)
Input
\(t \in [0,1]\) (1D)
\((x, t) \in [0,1]^2\) (2D)
Output
\((s, i, r)\) (functions of time)
\((s, i, r)(x,t)\) (spatiotemporal field)
Physics loss
ODE residuals via autograd.grad(y, t)
PDE residuals: grad(y,t) + grad(grad(y,x),x)
Boundary conditions
IC only
IC + Neumann BCs
Collocation
1D line \([0,T]\)
2D domain \([0,L]\times[0,T]\)
Extra parameter
—
Diffusion coefficient \(D\)
Training cost
\(O(\text{depth})\) per epoch
\(O(\text{depth})\) but 6–9 autograd.grad calls
The second spatial derivative requires two nested autograd.grad calls, making each physics-loss evaluation roughly 3× more expensive per collocation point than an ODE PINN. Using 500 collocation points (rather than 300 for the ODE case) still keeps each epoch under 0.1 s on a modern CPU.
10 Spatial vs. temporal observations
In practice, spatial observations are often even sparser than temporal ones. The PINN trained here uses only 80 spatial–temporal data points (\(20 \times 4\) time slices) yet reconstructs the full 2D field through the PDE physics. This illustrates the core strength of PINNs for spatiotemporal inverse problems: physics replaces data where data are absent.
Note
Extensions
2D and 3D domains: the same architecture handles higher-dimensional spaces by adding inputs; the autograd Laplacian \(\nabla^2 u\) requires one gradient per spatial dimension plus the second derivative.
Heterogeneous diffusion: replace scalar \(D\) with a spatially varying \(D(x)\), learned as a separate sub-network.
Anisotropic spread: use a diffusion tensor \(\mathbf{D}(x)\) to model road-network or commuter-network-driven transmission.
Multi-species systems: add a vector compartment (e.g., mosquitoes in malaria) with its own diffusion and reaction terms.
11 Series summary
This series covered the foundational PINN toolkit for epidemic and dynamical-systems modelling:
ODE solver in forward pass; adjoint method; partial-physics hybrid
This post
Reaction-diffusion PDEs; second spatial derivatives; travelling waves
12 References
1.
Murray JD. Mathematical biology I: An introduction. 3rd ed. New York: Springer; 2003. doi:10.1007/b98868
2.
Noble JV. Geographic and temporal development of plagues. Nature. 1974;250:726–9. doi:10.1038/250726a0
3.
Kermack WO, McKendrick AG. A contribution to the mathematical theory of epidemics. Proceedings of the Royal Society of London Series A. 1927;115(772):700–21. doi:10.1098/rspa.1927.0118
4.
Hethcote HW. The mathematics of infectious diseases. SIAM Review. 2000;42(4):599–653. doi:10.1137/S0036144500371907
5.
Murray JD. Mathematical biology II: Spatial models and biomedical applications. 3rd ed. New York: Springer; 2003. doi:10.1007/b98869
Raissi M, Perdikaris P, Karniadakis GE. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics. 2019;378:686–707. doi:10.1016/j.jcp.2018.10.045
8.
Tartakovsky AM, Marrero CO, Perdikaris P, Tartakovsky GD, Barajas-Solano D. Physics-informed deep neural networks for learning parameters and constitutive relationships in subsurface flow problems. Water Resources Research. 2020;56(5):e2019WR026731. doi:10.1029/2019WR026731