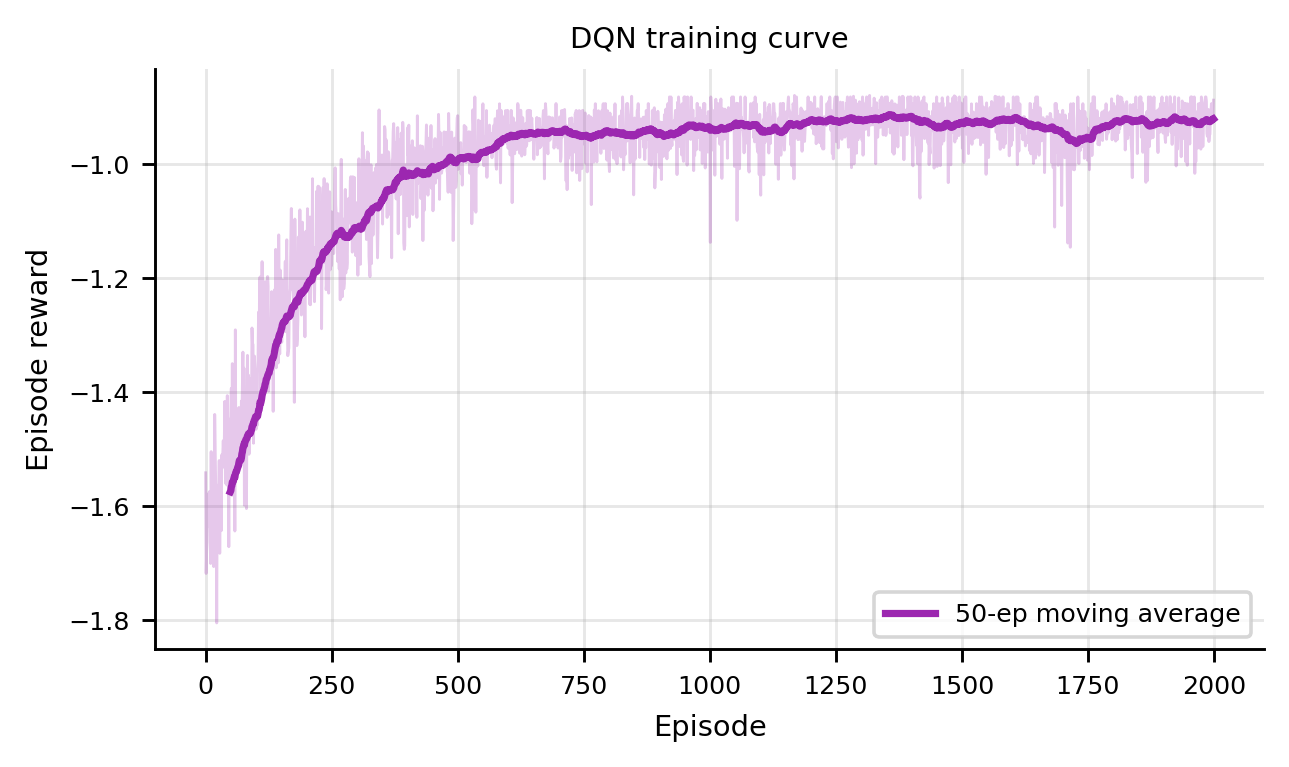
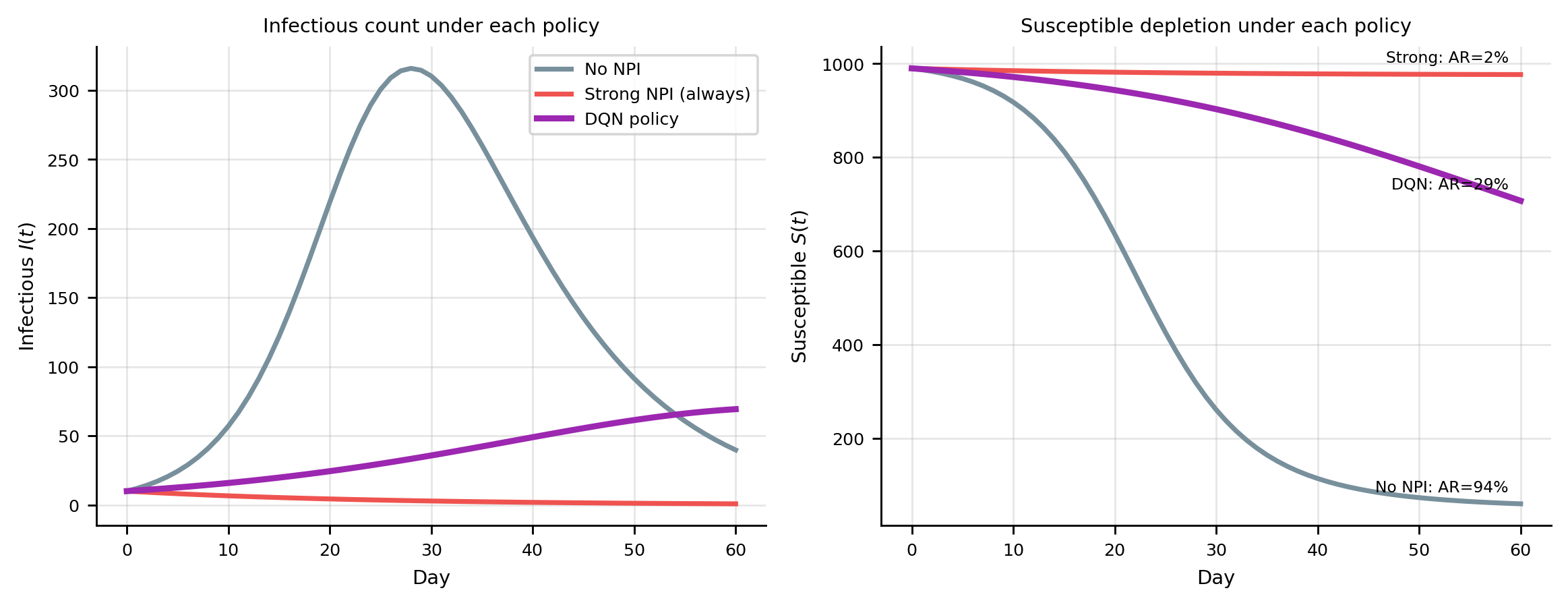
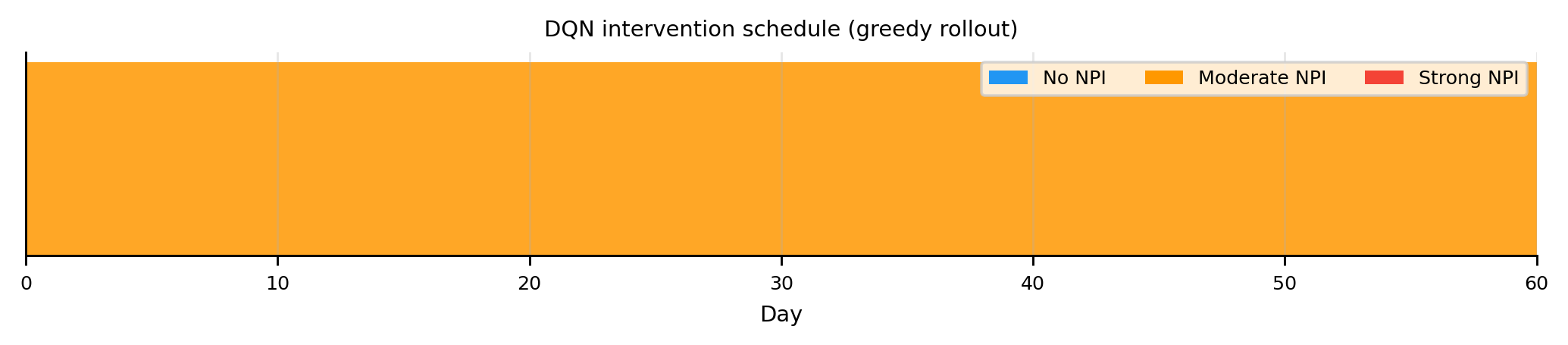
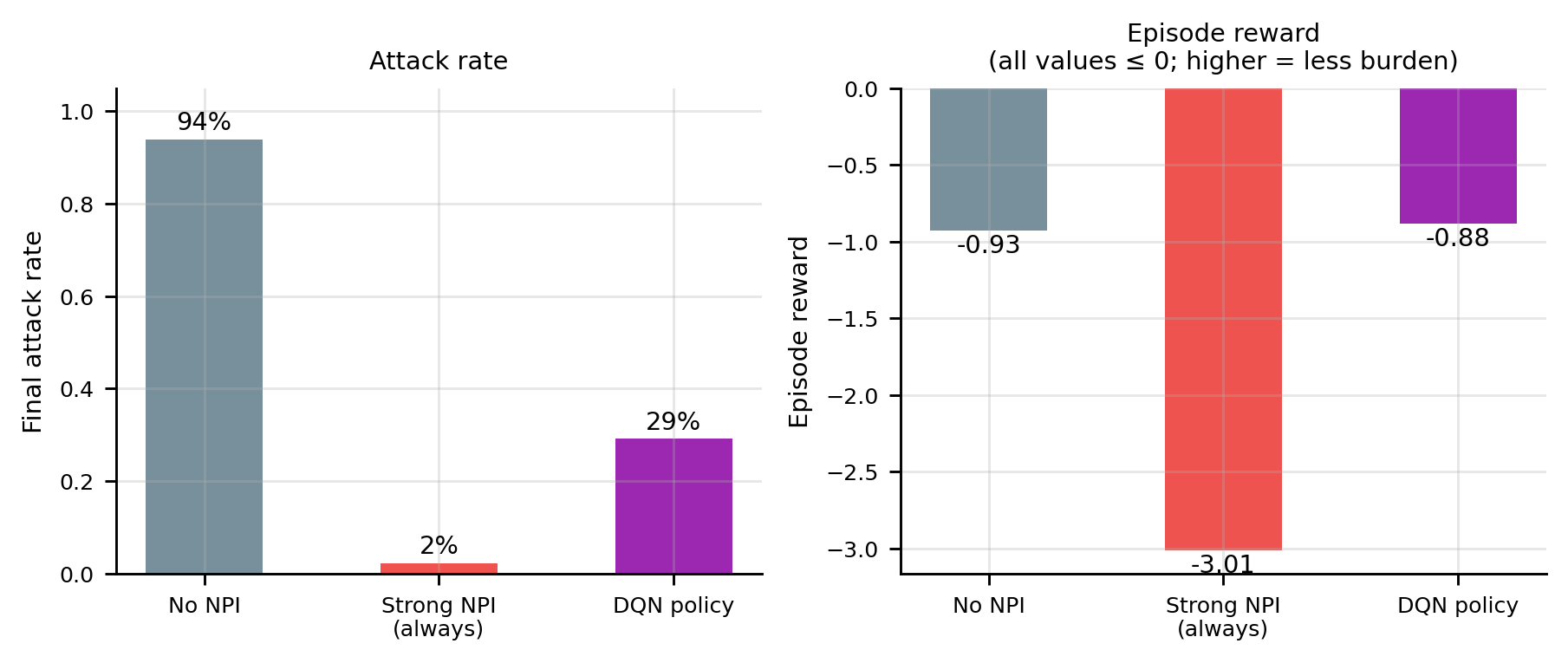
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from collections import deque
import random
torch.manual_seed(42)
np.random.seed(42)
random.seed(42)
plt.rcParams.update({
"figure.dpi": 130,
"axes.spines.top": False,
"axes.spines.right": False,
"axes.grid": True,
"grid.alpha": 0.3,
"font.size": 8,
"axes.titlesize": 8,
"axes.labelsize": 8,
"xtick.labelsize": 7,
"ytick.labelsize": 7,
"legend.fontsize": 7,
})
C0, C1, C2 = "#2196F3", "#FF9800", "#F44336" # action colours
C_DQN = "#9C27B0"
C_NONE = "#78909C"
C_STRONG = "#EF5350"
# ── Environment ───────────────────────────────────────────────────────────────
class SIREpidemicEnv:
"""
SIR epidemic as an MDP.
State : np.array([I/N, t/T]) in [0, 1]²
Actions: 0 = no NPI (β × 1.00, cost 0.000)
1 = moderate (β × 0.50, cost 0.010)
2 = strong (β × 0.20, cost 0.050)
Reward : −(new_infections / N) − cost[action]
"""
REDUCTION = np.array([1.00, 0.50, 0.20])
COST = np.array([0.000, 0.010, 0.050])
def __init__(self, beta=0.3, gamma=0.1, N=1_000, T=60, dt=1.0):
self.beta0 = beta
self.gamma = gamma
self.N = float(N)
self.T = float(T)
self.dt = dt
self.reset()
def reset(self):
self.S = self.N - 10.0
self.I = 10.0
self.R = 0.0
self.t = 0.0
return self._obs()
def _obs(self):
return np.array([self.I / self.N, self.t / self.T], dtype=np.float32)
def step(self, action):
beta_eff = self.beta0 * self.REDUCTION[action]
new_inf = beta_eff * self.S * self.I / self.N * self.dt
new_rec = self.gamma * self.I * self.dt
new_inf = min(new_inf, self.S) # can't infect more than available
self.S -= new_inf
self.I = max(self.I + new_inf - new_rec, 0.0)
self.R += new_rec
self.t += self.dt
reward = -(new_inf / self.N) - self.COST[action]
done = self.t >= self.T
return self._obs(), reward, done
# ── Q-Network ─────────────────────────────────────────────────────────────────
class QNetwork(nn.Module):
"""Feedforward Q-function: state → Q-values for each action."""
def __init__(self, state_dim=2, n_actions=3, hidden=64):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, hidden), nn.ReLU(),
nn.Linear(hidden, hidden), nn.ReLU(),
nn.Linear(hidden, n_actions),
)
def forward(self, x):
return self.net(x)
# ── Replay buffer ──────────────────────────────────────────────────────────────
class ReplayBuffer:
def __init__(self, capacity=10_000):
self.buf = deque(maxlen=capacity)
def push(self, s, a, r, s_next, done):
self.buf.append((s, int(a), float(r), s_next, float(done)))
def sample(self, batch_size):
batch = random.sample(self.buf, batch_size)
s, a, r, s2, d = zip(*batch)
return (torch.tensor(np.array(s), dtype=torch.float32),
torch.tensor(a, dtype=torch.long),
torch.tensor(r, dtype=torch.float32),
torch.tensor(np.array(s2), dtype=torch.float32),
torch.tensor(d, dtype=torch.float32))
def __len__(self):
return len(self.buf)
# ── DQN Agent ─────────────────────────────────────────────────────────────────
class DQNAgent:
"""
DQN with experience replay and a soft-updated target network.
Bellman target:
y = r + γ · max_a' Q_target(s', a') (non-terminal)
y = r (terminal)
"""
def __init__(self, state_dim=2, n_actions=3, hidden=64,
lr=5e-4, gamma=0.99, tau=0.01,
eps_start=1.0, eps_end=0.05, eps_decay=0.995,
batch_size=64):
self.n_actions = n_actions
self.gamma = gamma
self.tau = tau
self.eps = eps_start
self.eps_end = eps_end
self.eps_decay = eps_decay
self.batch_size = batch_size
self.policy_net = QNetwork(state_dim, n_actions, hidden)
self.target_net = QNetwork(state_dim, n_actions, hidden)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.target_net.eval()
self.opt = torch.optim.Adam(self.policy_net.parameters(), lr=lr)
self.buffer = ReplayBuffer()
# ε-greedy action selection
def act(self, state, greedy=False):
if not greedy and random.random() < self.eps:
return random.randrange(self.n_actions)
with torch.no_grad():
q = self.policy_net(torch.tensor(state).unsqueeze(0))
return q.argmax().item()
# One gradient step on a random minibatch
def update(self):
if len(self.buffer) < self.batch_size:
return None
s, a, r, s2, done = self.buffer.sample(self.batch_size)
q_pred = self.policy_net(s).gather(1, a.unsqueeze(1)).squeeze(1)
with torch.no_grad():
q_next = self.target_net(s2).max(1)[0]
q_targ = r + self.gamma * q_next * (1.0 - done)
loss = nn.functional.mse_loss(q_pred, q_targ)
self.opt.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.policy_net.parameters(), 1.0)
self.opt.step()
# Soft-update target network: θ_target ← τθ + (1−τ)θ_target
for p, tp in zip(self.policy_net.parameters(),
self.target_net.parameters()):
tp.data.copy_(self.tau * p.data + (1.0 - self.tau) * tp.data)
return loss.item()
def decay_epsilon(self):
self.eps = max(self.eps_end, self.eps * self.eps_decay)