set.seed(1)
# Simulate model outputs for 6 districts
districts <- data.frame(
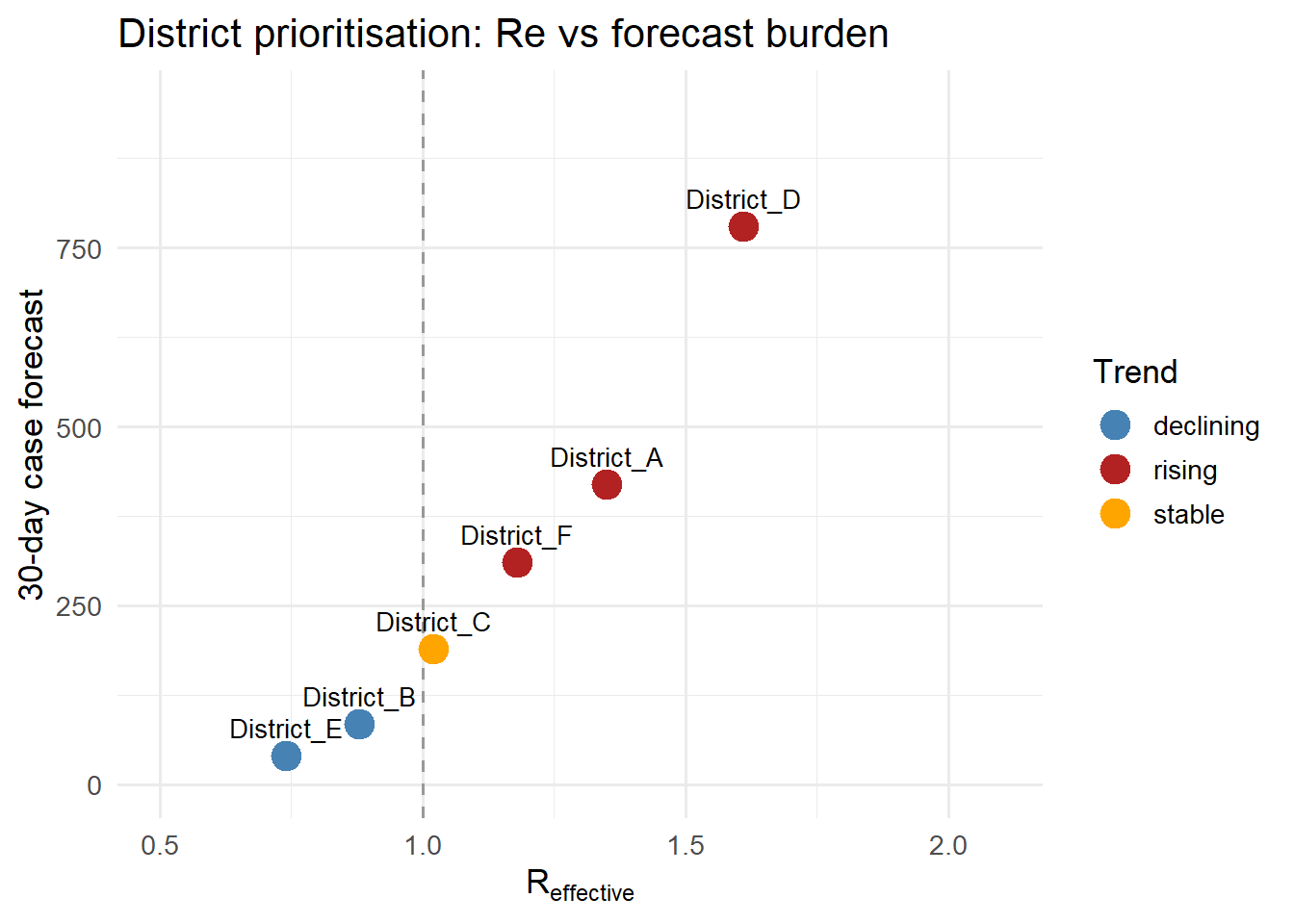
district = paste0("District_", LETTERS[1:6]),
Re_median = round(c(1.35, 0.88, 1.02, 1.61, 0.74, 1.18), 2),
Re_lo = round(c(1.10, 0.72, 0.85, 1.30, 0.55, 0.95), 2),
Re_hi = round(c(1.62, 1.07, 1.22, 1.98, 0.96, 1.44), 2),
forecast_30d = c(420, 85, 190, 780, 40, 310),
vax_pct = c(62, 81, 74, 55, 88, 70),
stringsAsFactors = FALSE
)
districts$trend <- ifelse(districts$Re_median > 1.1, "rising",
ifelse(districts$Re_median < 0.9, "declining", "stable"))
# Template-based fallback (no API needed)
template_sitrep <- function(row) {
status <- switch(row$trend,
rising = paste0("ALERT: R_eff = ", row$Re_median, " (", row$Re_lo, "–",
row$Re_hi, "), indicating sustained growth."),
declining = paste0("IMPROVING: R_eff = ", row$Re_median, " (", row$Re_lo,
"–", row$Re_hi, "), transmission declining."),
paste0("STABLE: R_eff = ", row$Re_median, " (", row$Re_lo, "–",
row$Re_hi, "), situation stable.")
)
vax_note <- if (row$vax_pct < 65) "Vaccination coverage below 65% — accelerate campaign." else
"Vaccination coverage adequate."
paste0(row$district, " | ", Sys.Date(), "\n",
status, "\n",
"30-day forecast: ", row$forecast_30d, " cases. ",
vax_note)
}
# Generate all reports
reports <- lapply(seq_len(nrow(districts)), function(i) {
template_sitrep(districts[i, ])
})
names(reports) <- districts$district
cat(reports[["District_A"]], "\n\n")