Self-Attention and Transformers: The Architecture Behind LLMs
Attention is a learned weighted average over past time steps. Build it from scratch in R by solving a concrete prediction task, then see how the full transformer scales the idea.
machine learning
transformers
attention
deep learning
R
Author
Jong-Hoon Kim
Published
April 24, 2026
1 Why transformers matter for epidemic intelligence
“Attention Is All You Need” by Vaswani et al. (1) is likely the most cited paper in the field of deep learning. It introduced the transformer architecture, which rendered recurrent networks obsolete for sequence modeling. The transformer architecture they introduced is now the foundation of every large language model and of the time-series forecasting models emerging in computational epidemiology, including Temporal Fusion Transformer (2) and TimeGPT (3).
Understanding transformers has practical payoffs including the following:
Time-series forecasting: attention-based models can learn which past epidemic weeks are most informative for the next-week forecast — something fixed moving averages cannot do.
LLM integration: LLMs attend to every part of your prompt when generating each output token. Understanding this mechanism makes you a better prompt engineer.
2 The prediction problem
An epidemic time series has temporal structure: next week’s case count depends on recent weeks, but not all weeks equally. The key question is which past weeks matter most, and by how much.
The simplest forecaster is a moving average (MA): predict next week as the mean of the last \(k\) weeks. This treats all lags equally. Attention learns a weighted average where the weights are optimised to minimise prediction error.
To make this concrete, we generate a 40-week epidemic series and set up a one-step-ahead forecasting task: given the last \(k = 5\) weeks, predict the next week’s case count.
The series is constructed so that both lag 1 and lag 2 carry genuine predictive information. Many respiratory pathogens have an incubation period of roughly two weeks, so today’s reported cases reflect both recent transmission (lag 1) and infections acquired two weeks ago (lag 2). We embed this structure explicitly: the series is the sum of a slow-moving epidemic envelope and a two-week alternating cycle (high week / low week), mimicking a reporting rhythm or biological echo. Lag 2 is in phase with the current week (both land on the same high or low week), while lag 1 is out of phase — making both lags necessary for a good forecast.
Code
set.seed(42)n <-40t_seq <-1:n# Slow-moving epidemic envelope (peaks at week 20)envelope <-70*exp(-((t_seq -20)^2) /80) +15# 2-week alternating cycle: high/low weeks (reporting rhythm or incubation echo)biweekly <-15*cos(pi * t_seq) # +15 on odd weeks, -15 on even weeks# Small AR(1) noisenoise <-numeric(n)noise[1] <-rnorm(1, 0, 7)for (t in2:n) noise[t] <-0.20* noise[t -1] +rnorm(1, 0, 7)cases <-pmax(1, round(envelope + biweekly + noise))k <-5# look-back window# Sliding-window dataset: col 1 = lag 1 (most recent), col k = lag k (oldest)n_pred <-length(cases) - kX_mat <-do.call(rbind, lapply( (k +1):length(cases),function(i) rev(cases[(i - k):(i -1)])))y_vec <- cases[(k +1):length(cases)]cat("Forecasting steps:", n_pred, "\n")
where \(\boldsymbol{\alpha} \in \mathbb{R}^k\) are unnormalized attention logits — the parameters we learn. The softmax ensures weights are non-negative and sum to 1. We find \(\boldsymbol{\alpha}\) by minimising mean squared prediction error with gradient descent.
This is the core idea behind every transformer, i.e., learning which positions to attend to. In the following sections, we will see how the idea is generalized to the transformer architecture.
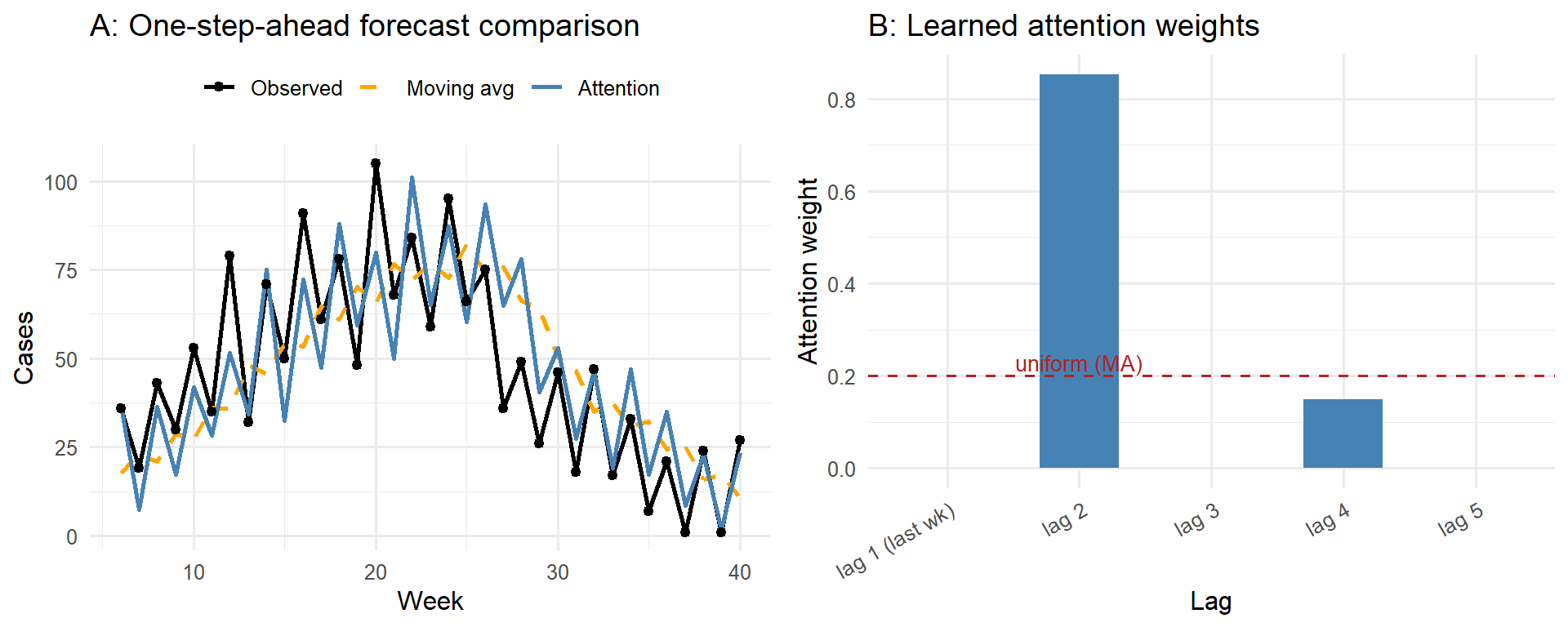
Left: one-step-ahead forecasts. Attention (blue) tracks the epidemic curve more closely than the moving average (orange) by learning non-uniform lag weights. Right: learned attention weights. Lags 2 and 4 (the even lags, in-phase with the 2-week cycle) receive all the weight; lags 1, 3, and 5 (out-of-phase) receive zero. A fixed moving average wastes weight on the out-of-phase lags and is therefore a worse predictor.
The dashed red line in panel B is the uniform weight \(1/k\) that the moving average uses. The learned weights tell a clear story: lags 2 and 4 (the even lags) receive all the weight; lags 1, 3, and 5 receive none. This is the correct discovery — the two-week alternating cycle means every other week is in the same phase as the current week. Lag 1 (one step back) is out of phase: its biweekly component is anti-correlated with the target, so attending to it hurts prediction. The uniform MA does not know this and assigns equal weight to all five lags, averaging in the anti-phase lags and degrading accuracy. Attention finds the phase structure automatically from the data.
5 From weighted average to full self-attention
The predictor above has one limitation: the weights \(\mathbf{w}\) are fixed once trained — they do not adapt to the current value of the sequence. If the epidemic is accelerating versus plateauing, the optimal lag weights differ.
The transformer’s self-attention solves this by making the weights content-dependent. Each position produces a query \(\mathbf{q}\) (“what context am I looking for?”) and keys \(\mathbf{k}_j\) (“what does position \(j\) offer?”). The attention weight from position \(i\) to position \(j\) is:
When the epidemic is growing steeply, the query for the current position will be similar to keys of recent high-growth periods, concentrating weight there. When the epidemic plateaus, the query changes and the attention pattern shifts. This is impossible with a fixed \(\mathbf{w}\).
Run \(h\) attention patterns in parallel; different heads may learn short-range vs long-range dependencies
Causal masking
For forecasting, mask future positions so position \(t\) only attends to positions \(\leq t\)
Feed-forward sublayer
Per-position MLP applied after attention (nonlinear feature transform)
Layer normalisation + residuals
Stable training through depth
Positional encoding
Inject position information since attention itself is permutation-invariant
Stack 6–96 such blocks, pre-train on token prediction at scale, and the result is a model that reasons across arbitrarily long contexts — the same mechanism that allows Claude or GPT to follow a 10,000-word prompt consistently.
6 Practical takeaway
Attention = learned weighted average over context, adapted to content at each position.
For epidemic forecasting, recent lags deserve higher attention — a fixed MA cannot express this, but learned attention can.
You do not need to implement a transformer from scratch in production. Use neuralforecast (Python) or Nixtla’s TimeGPT API for transformer-based epidemic forecasting.
Understanding the mechanism tells you why these models work and what their attention patterns mean when you inspect them.
7 References
1.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. In: Advances in neural information processing systems [Internet]. 2017. Available from: https://arxiv.org/abs/1706.03762
2.
Lim B, Arik SO, Loeff N, Pfister T. Temporal fusion transformers for interpretable multi-horizon time series forecasting. International Journal of Forecasting. 2021;37(4):1748–64. doi:10.1016/j.ijforecast.2021.03.012